


The Metric That Powers Our Predictions:
Understanding ROC AUC
How do you really know if a sports prediction model is any good? Most people think of simple accuracy—the percentage of games it called correctly. But what if we told you that accuracy can be dangerously misleading? A model that just picks the home team every time might have 54% accuracy, but it has zero predictive skill and would be a terrible guide for betting.
At Edge Staker, we go deeper. Our entire system is built around a more powerful and sophisticated metric used by data scientists at top tech companies: the Receiver Operating Characteristic and the Area Under the Curve, or .
It sounds complicated, but the concept is simple: measures a model’s ability to correctly distinguish between winners and losers. Understanding how we use it is the key to understanding the Edge Staker advantage.
What is ROC AUC? The Simple Explanation
Imagine you have all of today’s MLB games lined up. A perfect model would be able to sort this line perfectly, putting all the games that will be home-team wins at one end (assigning them high probabilities like 95%, 85%, 70%) and all the away-team wins at the other end (assigning them low home-win probabilities like 15%, 25%, 35%). A useless model, like a coin flip, would mix them all up randomly.
gives us a score from 0.5 to 1.0 that tells us how good our model is at this sorting task.
- 1.0: A perfect score. The model flawlessly separates every single winner from every loser. (The holy grail).
- 0.70 – 0.85: A good to excellent score. The model has a clear, reliable ability to distinguish between the two outcomes. This is the target range for a complex system like baseball prediction.
- 0.5: A useless score. The model is no better than random guessing or flipping a coin.
Unlike simple accuracy, which only cares about the final pick, evaluates the quality of the probability score itself. This is critical for betting, where knowing a team has a 65% chance to win is far more valuable than just being told “they will probably win.”
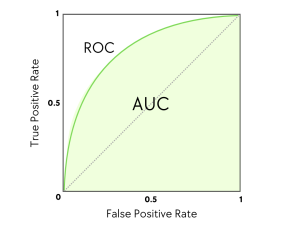 This graph illustrates the ROC curve and the Area Under the Curve (AUC). The green curve (ROC) shows the trade-off between correctly identified winners (True Positive Rate) and incorrectly identified losers (False Positive Rate) at various probability thresholds. The shaded green area represents the AUC, which quantifies the model’s overall ability to distinguish between outcomes. A perfect model would have an AUC of 1.0 (the entire square), while a random guess would follow the dotted diagonal line with an AUC of 0.5.
This graph illustrates the ROC curve and the Area Under the Curve (AUC). The green curve (ROC) shows the trade-off between correctly identified winners (True Positive Rate) and incorrectly identified losers (False Positive Rate) at various probability thresholds. The shaded green area represents the AUC, which quantifies the model’s overall ability to distinguish between outcomes. A perfect model would have an AUC of 1.0 (the entire square), while a random guess would follow the dotted diagonal line with an AUC of 0.5.
How Edge Staker Puts ROC AUC to Work
isn’t just a final report card for us; it’s the engine that drives our entire model creation process at three critical stages. This is our secret sauce.
1. Forging the Smartest Models
Behind the scenes, when our system builds a new predictive model, there are thousands of possible settings and configurations it can use. Our development process runs an internal competition to find the absolute best settings. The single metric used to keep score and declare a winner is . By optimizing for the best possible score, we ensure that from the very beginning, our models are designed to be expert sorters, finely tuned to separate winning teams from losing ones.
2. Crowning the Champions
Our proprietary training process doesn’t just build one model. It creates and tests dozens of them on different windows of historical data—some are experts on recent hot streaks, while others excel at seeing long-term trends.
To decide which ones are worthy of being part of our final tool, we run a “model tournament.” The sole judge of this tournament is . Only the model with the highest score on unseen data is crowned a “champion” and allowed to proceed. This guarantees that only the most skilled and proven models make it into our final prediction engine.
3. Creating the Expert Ensemble
The final, most powerful step in our process involves our ensemble engine. Instead of relying on a single prediction, Edge Staker combines the insights from all our “champion” models into one final, weighted prediction.
The weight given to each expert’s opinion is determined by its score. A model that scored an outstanding 0.75 in our tournament will have a much bigger say in the final prediction than one that scored 0.68. This ensures that our most powerful models have the most influence, giving you a final prediction that is robust, reliable, and backed by a committee of proven experts.
What This Means For You
Choosing to build our system around was a deliberate decision to give you a true, sustainable edge.
It means our models are less likely to be fooled by simple trends and better at understanding the true, underlying probabilities of a game. It means we can more accurately measure our confidence in a prediction, which is essential for identifying value in the betting market.
With Edge Staker, you’re not just getting a pick; you’re getting a sophisticated, data-driven probability powered by a metric designed to find the signal in the noise.